MỤC ĐÍCH
Thể hiện việc rà soát chính xác và dữ liệu HRMS để xác định sự hiện diện khối lượng các chất chọn lọc quan tâm và không xác định trong một mẫu rau bina so với mẫu rau bina trắng.
GIỚI THIỆU
Các phương pháp sàng lọc đa phân tích cần thiết để giám sát thực phẩm và các mẫu môi trường trên toàn cầu. Mục tiêu của các phương pháp này là loại bỏ các mẫu trong danh mục và xác định các mẫu không trong danh mục để định tính và định lượng. Đô nhạy phải phù hợp với các giới hạn quy định với dư lượng trong mẫu nền. Ngoài ra, phương pháp phải được xác nhận phù hợp với các yêu cầu lập pháp. Phương pháp này là phương pháp nhanh chóng, hiệu quả về chi phí và có quy trình hợp lý, từ khâu chuẩn bị mẫu đến báo cáo kết quả.
Ngày nay, các công nghệ khối phổ tứ cực LC-MS / MS hoặc GC-MS / MS đáp ứng các yêu cầu trên gọi là dạng kỹ thuật de-facto được sử dụng để thực hiện những phân tích này. Tuy nhiên, với số lượng không ngừng tăng lên của các chất phân tích được thêm vào danh mục giám sát và theo dõi, phạm vi của một phương pháp sàng lọc điển hình đang được gia hạn . Ngoài ra, yêu cầu sàng lọc các hợp chất ngoài danh mục ngày càng trở nên phổ biến. Do đó, nhiều phòng thí nghiệm đang tiến tới sàng lọc bằng kỹ thuật khối phổ có độ phân giải cao (HRMS), về lý thuyết, có thể theo dõi số lượng chọn lọc đồng thời cung cấp thông tin để giúp khám phá các hợp chất chưa biêt hoặc các chuyển hoá quan tâm.
Sử dụng dề dàng và hiệu quả của phân tích không chọn lọc, dữ liệu độc lập, loại phân tích (MS E và HDMS E )
loại, cùng với cổng thông tin khoa học tiên tiến. Hệ thống (UNIFI) dùng cho sàng lọc đa chất phân tích trong các mẫu thực phẩm và môi trường được chứng minh với nghiên cứu liên quan đến mẫu phân tích xác thực. Bài Ứng dụng này tập trung vào việc giới thiệu cách mới để người dùng có thể tuỳ chỉnh dữ liệu trong hệ thống thông tin khoa học trong trường thông tin thông thường. Chi tiết sẽ bao gôm cách thiết lập cách tiếp cận ngắn gọn, nhanh chóng, dễ dàng và nhât quán để tham khảo dữ liệu HRMS cho khả năng trả lời 4 câu hỏi trong hình 1 với một bước xử lý duy nhất
THỰC NGHIỆM
Phân tích mẫu và xử lý dữ liệu
Vials có chứa mẫu chiết xuất rau bina và mẫu chiết xuất rau bina thêm chuẩn với nồng độ 1,0 g / mL trong 100% acetonitril (ACN), được chuẩn bị bằng cách sử dụng QuEChERS, do một cộng tác viên cung cấp. Pha loãng mãu vơi nước theo tỷ lệ 1:1, tạo nồng độ mẫu nền 0,5 g / mL. Thực hiện tiêm 5µL. Dữ liệu không chọn lọc được phân tích độc lập, (MS E) được thu thập và xử lý trong UNIFI. Một ứng dụng trươc đó có ghi chú chi tiết các thông số được sử dụng để thu thập tập dữ liệu không chọn lọc và làm nổi bật tầm quan trọng của dữ liệu tổng hợp, cho phép cập nhật, thống nhất và tham khảo nhanh chóng trong tập dữ liệu đã được tạo ra.
Dữ liệu được phân chia dựa trên danh sách chọn lọc trong tổng số 529 phụ phẩm nông nghiệp và không rõ khối lượng quan tâm. Khối lượng quan tâm không được chọn lọc đã được làm rõ bằng cách sử dụng thiết bị phân tích. Phân tích này tập trung vào định tính chính xác, so sánh thứ cấp của những chất không xác định bằng giải pháp Ứng dụng Sàng lọc Thuốc trừ sâu Waters ® , để trả lời 3 câu hỏi (Được đánh dấu) trong số bốn câu hỏi được hiển thị trong Hình 1.
Cộng tác viên cho rằng mẫu rau bina có chứa dư lượng thuốc trừ sâu không có trong danh sách chất cấm. Với các dư lượng không chọn lọc, cộng tác viên muốn đánh giá cách mà những dư lượng này được phát hiện và làm rõ. Quy trình làm việc được mô tả chi tiết về các thực hiện này ở cuối bài ứng dụng này.
.png)
Hình 1. Các câu hỏi cơ bản cho các phương pháp sàng lọc đa dư lượng hiện đại
1- Đây là những hợp chất gì trong mẫu?
2- Trong mẫu còn chất nào khác?
3- Có bao nhiêu trong mẫu này?
Mục đích của các nghiên cứu điển hình này chỉ ra cách người dùng có thể nhận được từ việc tiêm mẫu vào một báo cáo chính xác, nhanh chóng và hiệu quả, cách có hệ thống và lặp lại bằng cách sử dụng quy trình làm việc, tham khảo và qua bộ lọc UNIFI. Quy trình làm việc được dùng cho phân tích định tính này thể hiện trong Hình 2. Dòng công việc (bên trái) là một loạt các bước cho phép người dùng rà soát dữ liệu HRMS một cách tổng quát và chính xác với mồi bước bao gồm một bộ lọc và chế độ xem. Thông tin được hiển thị cho phép người dùng thực hiện nhanh chóng quyết định cho câu trả lời ở Hình 1.
.png)
KẾT QUẢ VÀ THẢO LUẬN
Bảng 1 cho thấy danh sách các hợp chât có trong mẫu rau bina của cộng tác viên. Sau khi xem xét dữ liệu, tất cả các hơp chất chuẩn trong mẫu rau bina của cộng tác viên được báo cao. 9 hợp chất có trong danh sách chọn lọc 529 chất, 5 hợp chất không có trong danh sách chọn lọc được phát hiện thư câp với mẫu rau bina trắng hoặc bằng phương pháp sử dụng UNIFI kết hợp halogen. Để làm rõ khôi lượng 5 hợp chất này, đã thực hiện bằng cách sử dụng công cụ khám phá trong UNIFI,
.png)
Bảng 1. So sánh danh sách mẫu rau bina thêm chuẩn của cộng tác viên và và các hợp chất phù hợp trong quá trình sàng lọc đối với thuốc trừ sâu sử dụng Waters 'PSAS.
KẾT LUẬN
Độ nhạy - Việc sử dụng MS E cung cấp các tập dữ liệu chất không chọn lọc có đủ độ nhạy để phát hiện tiền chất và sản phẩm ion của thuốc trừ sâu với nồng độ dưới nồng độ MRL của chúng.
Tốc độ - Tốc độ quét để thu thập toàn diện dữ liệu MS E được đặt theo độ rộng peak của một phương pháp phát triển UPLC ® . Chu kỳ làm việc nhanh cho phép người dùng nắm bắt đủ điểm trên peak sắc ký cho cả tiền chất và các kênh sản phẩm ion trong một lần tiêm để tối đa hóa tiêu chí nhận dạng và kết quả định lượng.
Tính chọn lọc - Lựa chọn Apex 3D Peak và các thành phần làm tăng tính cụ thể và cho phép người dùng tham vấn dữ liệu các chất chọn lọc và không chọn lọc và khối lượng của chất chưa biết trong mẫu hỗn hợp mà không cần xử lý dữ liệu thô.
Hiệu quả - Việc sử dụng bộ lọc, quy trình làm việc và tra cứu một cách nhất quán, ngắn gọn và rà soát toàn diện các tập dữ liệu để cho phép người dùng đi từ tiêm đến kết quả chính xác nhanh chóng.
PHỤ LỤC: CÁC BƯỚC TRONG QUY TRÌNH LÀM VIỆC
Các bước quy trình làm việc 6–8: Sàng lọc không xác định sử dụng các tính năng so sánh thứ cấp và Đặc trưng liên kết halogen
Việc hợp thành dữ liệu đảm bảo tất cả các chất quan tâm được đưa vào cùng một tập dữ liệu để xem xét, thông qua một danh sách các chất xác định hoặc cho những chất có khối lượng chưa xác định. Không cần xử lý bổ sung để tìm kiếm chất chưa biết. Tất cả các tính năng được trích xuất thông qua thành phần đặc trưng.
Có một số cách để so sánh mẫu tham chiếu với mẫu không xác định trong UNIFI. Sự khác biệt lớn được hiển thị dễ dàng với chức năng so sánh nhị phân thể hiện cường độ đỉnh cơ sở (BPI) (Hình 3).
.png)
Hình 3. So sánh nhị phân - BPI: Nhận biết peak sắc ký quan tâm sử dụng cường độ peak cơ sở. Dấu vết đỏ là rau bina trống (tham chiếu), dấu vết màu xanh lam là
mẫu bina thêm chuẩn (chưa rõ) và sự khác biệt giữa các ô dấu vết xanhtrống và thêm chuẩn. Hộp màu xanh đánh dấu một khu vực khác biệt giữa rau bina trống
và rau bina thêm chuẩn được quan sát
Người dùng cũng có thể chọn hiển thị thông tin dưới dạng bảng được hiển thị khi sử dụng trong quá trình so sánh hai mẫu (Hình 4). Với việc áp dụng một bộ lọc đơn giản, người dùng có thể tập trung vào các ion quan tâm. Ví dụ: chỉ hiển thị khối lượng duy nhất cho mẫu không xác định, nằm trong khoảng từ 100–500 Da và có phản hồi lớn hơn một giá trị xác định.
Biểu đồ thành phần so sánh nhị phân (Hình 5) hiển thị khối lượng thành phần dưới dạng que. Điều này cho phép người dùng quan sát ngay lập tức và chọn khối lượng quan tâm khác nhau trong mẫu chưa biết so với mẫu tham chiếu. Sau khi được chọn, những vị trí khối lượng đươc quan tâm (được đánh dấu trong hộp màu vàng) có thể được gửi trực tiếp phần mềm phát hiện câu trúc
Về cơ bản, với hệ thống MS E và UNIFI, người dùng có thể kiểm tra, sắp xếp và hiển thị dữ liệu để báo cáo nhanh chóng.
.png)
Hình 4. So sánh nhị phân - Tóm tắt thành phần: Chế độ xem dạng bảng của
dữ liệu được thành phần hóa khi so sánh giữa rau bina trống (tham khảo) và
rau bina thêm chuẩn (chưa rõ). Cho phép người dùng xem phản hồi và tỷ lệ phản hồi cho tất cả các thành phần được phát hiện dựa trên mẫu tham khảo và mẫu chưa biết. Người dùng cũng có thể áp dụng một bộ lọc để hiển thị duy nhất kỹ thuật chưa biết, tham chiếu các thành phần duy nhất hoặc các thành phần chung.
.png)
Hình 5. So sánh nhị phân - Biểu đồ thành phần: Nhận dạng các khối lượng quan tâm, có thể được chọn và gửi trực tiếp đến bộ công cụ nhận dạng .
Khối lượng quan tâm chưa biết cũng có thể được phát hiện bằng cách sử dụng hàm đối sánh halogen (Hình 6). Trong một giai đoạn xử lý, mọi khối lượng chưa xác định được đánh giá sự có mặt của các nguyên tử clo và brom bằng cách sử dụng hiệu số khối lượng và cường độ đồng vị. Bước quy trình làm việc sử dụng một bộ lọc đơn giản để làm nổi bật các halogen chứa khối lượng trên ngưỡng cường độ, trong một phạm vi khối lượng xác định . Thông tin được chọn để hiển thị là thành phần tóm tắt, sắc ký đồ ion được chiết xuất và thông tin phổ (Hình 6). Bản tóm tắt thành phần nêu bật các thông tin như thời gian lưu, phản ứng và số lượng ion clo và brom được đề xuất. Các cửa sổ quang phổ cho phép người dùng nhanh chóng đánh giá từng hợp chất chứa halogen tiềm năng. Cửa sổ sắc ký hiển thị sắc ký đồ ion chiết xuất (XIC) của một khối lượng chất đã chọn. Có ba khối lượng được đánh dấu trong Hình 6. Điều này có nghĩa là ba trong số năm khối lượng được đánh dấu trong phép so sánh nhị phân (Hình 5) cũng đáp ứng các tiêu chí cho công cụ đối chiếu halogen. Các công cụ khác (không hiển thị) trong UNIFI cho phép phát hiện các khối lượng quan tâm chưa biết là phân mảnh phổ biến, khuyết khối lượng và mât tính trung tính. Đầy đủ khả năng phân tích đa biến (không được hiển thị) cũng có sẵn cho các thử nghiệm sàng lọc hoàn chỉnh chưa biết.
.png)
Hình 6. Mặc dù không cần quy trình xử ly, Các bước hiển thị quy trình làm việc này có thể hiện hợp chất halogen hóa quan tâm trong quá trình tiêm. Tiền chất và sản phẩm phổ ion cộng với một sắc ký đồ ion trong dịch chiết của tiền chất cũng được hiển thị.
Một loạt các công cụ làm nhận danh có sẵn trong UNIFI để giúp xác định khối lượng chất quan tâm chưa biết. Một trong số đó là Discovery Tool, cho phép người dùng gửi nhiều khối lượng cùng lúc để xác định cấu trúc trong 1 lần . Bất kỳ công thức đề xuất nào đáp ứng các tiêu chí đã đặt ra sẽ được gửi đến thư viện tìm kiếm.
Đây có thể là một thư viện UNIFI, lựa chọn các thư viện trong ChemSpider 4 hoặc toàn bộ thư viện ChemSpider. Tệp được tải xuống cho tất cả các thư viện tiềm năng và phân đoạn được thực hiện như là phần cuối cùng của quá trình định danh.
The discovery tools được giải thich chi tiết như sau;
Cài đặt Công cụ Khám phá:
■ Discovery Parameters - Chọn tìm kiếm trên ChemSpider hoặc bất kỳ Thư viện Khoa học UNIFI
■ Elemental Composition - Thành phần nguyên tố được thực hiện trên tất cả các hợp chất được gửi đến Discovery Tool
■ ChemSpider Search - Tất cả các công thức được đề xuất có i-Fit lớn hơn giá trị đã xác định cho thành phần nguyên tố đều được gửi để tìm kiếm cơ sở dữ liệu. Trong ví dụ được hiển thị ở đây, ba cơ sở dữ liệu trong ChemSpider đã được tìm kiếm (ChEBI, ChEMBLE và Pesticide Common Names).
■ Fragment Match - Các ion phân mảnh có năng lượng chính xác cao được kết hợp với sự phân chia liên kết thông minh tự động đã tải xuống theo têm tệp “.mol” cho các lần truy cập tiềm năng từ các thư viện ChemSpider.
Kết quả từ việc gửi 5 khối lượng chất quan tâm (được đánh dấu trong Hình 5) trên Discovery tool được thể hiện trong Hình 7. Kết quả bảng bên phải trong Hình 7 cho thấy tất cả các thành phần nguyên tố được dự đoán với kết quả tìm kiếm cơ sở trên dữ liệu và so sánh thông tin phân mảnh cho 5 chất quan tâm. Các kết quả này có thể được sắp xếp theo tiêu đề cột và trong trường hợp này, chúng được xếp hạng bằng cách sử dụng cường độ dự đoán. Lượt truy cập nhiều nhất được đánh dấu với khối lượng chât 318.1979. Chất này có thành phần nguyên tố được dự đoán là
C 18 H 24 FN 3O với kết quả tìm kiếm cơ sở dữ liệu là penflufen. Cấu trúc của penflufen từ cơ sở dữ liệu được sử dụng để thực hiện phân mảnh phù hợp trong đó 9 ion từ phổ của sản phẩm được so trùng với sai số khối lượng la 2mDa. Điều này mang lại cường độ dự đoán trong số 77% các đỉnh quang phổ có trong dữ liệu năng lượng cao, cung cấp độ tin cậy tốt về kết quả này. Thông tin quang phổ cho
các ion tiền chất và sản phẩm của khối lượng chất được đánh dấu được hiển thị ở bên trái của Hình 7.
Sau khi xem xét các kết quả của Discovery tool, người dùng có thể chọn nút gán bao gồm các nhận dạng dự đoán vào report cuối cùng.
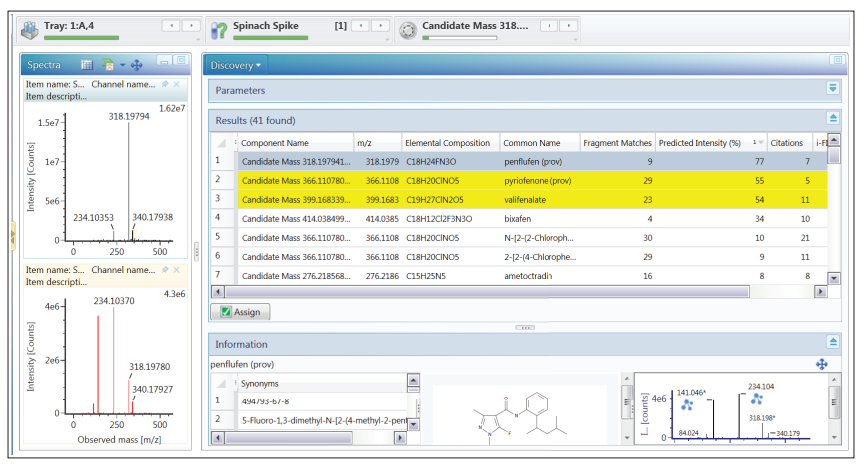
Hình 7. Kết quả từ Discovery tool cho cấu trúc 5 chất có khối lượng quan tâm chưa biết được phân lập bằng cách sử dụng so sánh nhị phân, biểu đồ thành phần (Hình 5).
Việc sử dụng hàng loạt công cụ halogen match, binary compare và batch elucidation cho phép xác định năm hợp chất chưa biết trong mẫu rau bina thêm chuẩn. Các hợp chất này (ametoctradin, bixafen, penfluen, pyriofenone và valifenalate) không được cộng tác viên dự đoán trước khi phân tích nhưng đã được tìm thấy là đúng khi xem xét phân tích cuối cùng.